VTK/ThreadedStreamingPipeline
The current design of VTK pipeline is very comprehensive in the way that it can support streaming of structured data as well as allowing users to develop unstructured data streaming (see streaming, VTK's Pipeline). However, it is very difficult (if not possible) to have modules of a pipeline executed simultaneously in a multi-threaded environment (vs.dividing data into smaller pieces and run through multiple instances of that pipeline). This is because in a demand-driven pipeline, when a consumer demands data, it has to wait (and lock) for all of its upstream modules to update. This only serves well with a single-threaded updating mechanism. To make this threaded, an event-driven model has to added. Modules can process data as soon as all of its inputs arrive and signal its downstream modules to execute when it is done processing.
vtkThreadedStreamingPipeline
Inheriting from vtkCopmositeDataPipeline, this executive implements a Push (event-driven) on top of the current demand-driven model of VTK. It also provides supports for multi-threaded execution of the pipeline by introducing a scheduler to manage the update processes. Out of the nutshell, the executive provides two main operators sitting as two functions: Pull() and Push(). There are multiple overloaded versions of these two functions to aid on the algorithm development process, the two most basic forms are: <source lang="cpp"> Pull(vtkThreadedStreamingPipeline *exec, vtkInformation *info=NULL); Push(vtkThreadedStreamingPipeline *exec, vtkInformation *info=NULL); </source>
Each of them takes on an executive and an information set key. Their main task is to trigger updates on the input exec. By default, Push() will also propagate updates to exec's downstream module after it finishes updating while Pull() will forward the requests to upstream modules before the exec updates. Both Push() and Pull() doesn't really call the algorithm exec itself, instead it just passes it to a scheduler, which is responsible for multi-threaded updates of the pipeline.
The Pull() works very similar to the VTK demand-driven pipeline update mechanism but it promotes task parallelism. Another reason for having Pull() separately is that it would not interfere with the current demand-driven pipeline and we can maintain backward compatibility for prior algorithms.
The Push() is the main operator and gateway for efficient multi-threaded streaming as it supports both task and pipeline parallelism. Though both Pull() and Push() uses the same scheduler, the distinguishing of pipeline parallelism in Push() against Pull() is lying in the function returns. When Pull() is called, the function only returns after all the upstream modules including exec are up-to-date. All the modules maybe updated multi-threaded, however, they will work only on a single request and there will not be any overlappping of processing different data-blocks. On the other hand, Push() will return control as soon as the scheduler determines that there are idling threads on its queue and exec downstreams can take more data. Thus, pipelining execution of multiple data-blocks are allowed when multiple Push() get called sequentially.
The second parameter, info, of the two function calls are used to incorporate specific information to the actual VTK request that each algorithm will process during its update. The use for this is to pass extents or piece number information to algorthms.
One variation of Pull() and Push() is: <source lang="cpp"> Pull(vtkstd::vector<vtkThreadedStreamingPipeline*> execs, vtkInformation *info=NULL); Push(vtkstd::vector<vtkThreadedStreamingPipeline*> exec, vtkInformation *info=NULL); </source> where multiple executives will be put on the scheduler at the same time, this would both avoid repeated updates with Push pipelines and allow task parallelism across different update branch in Pull pipelines.
Another variation of Pull() and Push() is: <source lang="cpp"> Pull(vtkInformation *info=NULL); Push(vtkInformation *info=NULL); </source> which will automatically look for upstream/downstream executives and call Push()/Pull() using the previous interface.
Streaming Examples
Using Push(), the RequestData() of ImageDataGenerator should look like: <source lang="cpp"> while (this->EndOfStream()) {
// Read in next piece ... this->Push();
} </source>
Using Pull(), the RequestData() of ImageDataMerger should look like: <source lang="cpp"> vtkInformation *info; for(int i=0;i<numPieces;i++)
info->Set(PIECE_NUMBER(), i) this->Pull(info);
} </source>
Note that the implementations of ImageDataStreamer and ImageDataMerger in Push() and Pull() streaming model are different. In the Pull() streaming model, the ImageDataGenerator has to honor the PIECE_NUMBER() value coming from its request info and just produce a single piece of data based on that number.
LOD Rendering Examples
Using Push(): <source lang="cpp"> void viewportChangedEvent() {
vtkstd::vector<vtkThreadedStreamingPipeline*> execs;
execs.push_back(DataAccess1->GetExecutive());
execs.push_back(DataAccess2->GetExecutive());
while (LOD>0) {
DataAccess1->SetLOD(LOD);
DataAccess2->SetLOD(LOD);
vtkThreadedStreamingPipeline::Push(execs);
LOD = LOD - 1;
}
} </source>
Using Pull(): <source lang="cpp"> void viewportChangedEvent() {
vtkstd::vector<vtkThreadedStreamingPipeline*> execs;
execs.push_back(DataAccess1->GetExecutive());
execs.push_back(DataAccess2->GetExecutive());
vtkInformation *info=...;
while (LOD>0) {
info->Set(PIECE_NUMBER(), LOD);
vtkThreadedStreamingPipeline::Pull(execs, info);
LOD = LOD - 1;
}
} </source>
Note that Push() supports pipeline parallelism, Pull() does not
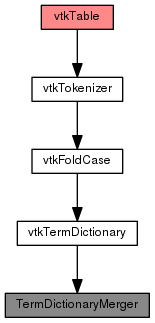
Streaming Text Analysis Pipeline
vtkTable is not a subclass vtkAlgorithm, it is just a data object. TermDictionaryMerger has to be implemented in addition to vtkTermDictionary because vtkTermDictionary doesn't accumulate dictionary across different computations. So TermDictionaryMerger maintains a "global" set of dictionary only get cleared once during its initialization, and every time it executes, it Dump() out the current table.
Using Push(), for example running on a thread that gets executed every second: <source lang="cpp"> void onTimer() {
// Construct new documents in vtkTable documents = vtkSmartPointer<vtkTable>::New(); // Add columns using vtkUnicodeStringArray ... tokenizer->SetInputConnection(0, documents->GetProducerPort()); vtkThreadedStreamingPipeline::Push(tokenizer);
} </source>
Using Pull(), for example of streaming 10 different documents through the term dictionary <source lang="cpp"> for (int i=0; i<10; i++) {
// Construct new documents in vtkTable documents = vtkSmartPointer<vtkTable>::New(); // Add columns using vtkUnicodeStringArray ... tokenizer->SetInputConnection(0, documents->GetProducerPort()); vtkThreadedStreamingPipeline::Pull(merger);
} </source>
vtkExecutionScheduler
vtkExecutionScheduler is the implementation of the threaded execution queue, here is briefly how it works:
- Allow independent modules to be updated simultaneously
- Use a priority queue
- Use topological order of the dataflow DAG to assign each module a priority rank
- Lower ranks get executed first
- Streaming piece numbers attach to priority rank
