ParaView/UsersGuide/Filtering Data: Difference between revisions
| Line 167: | Line 167: | ||
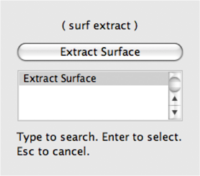
Searching through these lists of filters, particularly the full alphabetical list, can be cumbersome. To speed up the selection of filters, you should use the quick launch dialog. When the ctrl and space keys together on Windows or Linux or the alt and space keys together on Macintosh, ParaView brings up a small, lightweight dialog box like the one shown here. Type in words or word fragments that are contained in the filter name, and the box will list only those sources and filters that match the terms. Hit enter to add the object to the pipeline browser. | Searching through these lists of filters, particularly the full alphabetical list, can be cumbersome. To speed up the selection of filters, you should use the quick launch dialog. When the ctrl and space keys together on Windows or Linux or the alt and space keys together on Macintosh, ParaView brings up a small, lightweight dialog box like the one shown here. Type in words or word fragments that are contained in the filter name, and the box will list only those sources and filters that match the terms. Hit enter to add the object to the pipeline browser. | ||
<center>[[File: | <center>[[File:ParaView_UsersGuide_QuickLaunchDialog.png|200px|link=]]</center> | ||
<center>'''Figure 12. Figure . Quick Launch'''</center> | <center>'''Figure 12. Figure . Quick Launch'''</center> | ||
Revision as of 02:36, 11 December 2010
- Manipulating Data
In the course of either searching for information within data or in preparing images for publication that help to explain data, it is often necessary to process the raw data in various ways. Examples include slicing into the data to make the interior visible, extracting regions that have particular qualities, and computing statistical measurements from the data. All of these operations involving taking in some original data and using it to compute some derived quantities. This chapter explains how one controls the data processing portion of ParaView's visualization pipeline to go about doing such analyses.
A filter is the basic tool that one uses to manipulate data. If data is a noun, then a filter is the verb that operates on the data. Filters operate by ingesting some data, processing it and producing some other data. In the abstract sense a data reader is a filter too because it ingests data from the file system. ParaView creates filters then when you open data files, and when you instantiate new filters form the Filters menu. The set of filters you create becomes your visualization pipeline, and that pipeline is shown in ParaView's Pipeline Browser.
Filter Parameters
Each time a data set is opened from a file, a source is selected, a filter is applied, or an exiting reader, source, or filter is selected in the Pipeline Browser, ParaView updates the Object Inspector for the corresponding output data set. From the Object Inspector you can specify the display representation of this data set and the parameters for the corresponding reader, source, or filter. The Object Inspector also provides some statistical information about the data set once it has been loaded or created. The Object Inspector has three tabs: Properties, Display, and Information; these will be described in more detail in this chapter.
Properties
From the Properties tab, you can modify the parameters of the reader, source, or filter being used to load or create a new data set. A filter that extracts an isocontour will have a control with which to set the isovalue to extract at for example. The controls and information provided on the tab are dependent upon the reader, source, or filter selected in the Pipeline Browser; these features are located below the row of buttons labeled Apply, Reset, Delete and ? (Help).
When a reader, source, or filter is first selected, the associated data set is not immediately created. By default (unless you turn on Auto-Accept in ParaView’s options) it will not happen until the Apply button is pressed. Pressing the Apply button passes the values on the Properties tab to the data processing engine. When the values of the user interface controls located below the row of Apply, Reset, and Delete buttons do not match the values of the underlying data set, the Apply button will be highlighted (in blue or green depending on your operating system). This is the case when a reader, source, or filter is first added to the visualization pipeline or when the value of at least one of the user interface controls on the Parameters tab has been modified. This delayed acceptance behavior is essential when working with large data sets, for which any given operation may not complete until after a significant delay.
Beside the Apply button is the Reset button. It sets the GUI controls for this data set to the state they were in the last time Apply was pressed. If Apply has not been pressed yet, the controls are set to their initial values for this data set. Apply and Reset allow you to review changes you make to filter settings before they become active. If you make a mistake and Apply a change that you do not like, you can use the Undo button on the Undo/Redo toolbar to reverse the action. You can in fact undo all the way to the beginning of your ParaView session and redo back up to your most recent Apply.
Pressing the Delete button (beside the Reset button) when it is enabled removes the current filter (that selected in the Pipeline Browser) from the visualization pipeline. If the output of that filter is being used as the input to another filter, the Delete button will be disabled. To delete a data set that is in such a state, all filters that are using it as input must be deleted first. If you wish to delete all of the data sets currently loaded in ParaView instead of just the current data set, select Delete All from the Edit menu.
The specific parameter control widgets vary from filter to filter and sometimes vary depending on the exact input to the filter. In all cases the widgets give you control over exactly what the filter does. If you are unsure of what a filter does or what the controls do, hit the ? button to the right of the Delete button to open up the documentation for that filter.
Note that ParaView attempts to provide reasonable default settings for the parameter settings and to some extent guards against invalid entries. A numeric entry box will not let you type in non-numerical values for example. Sliders and spin boxes also typically have minimum and maximum settings beyond which they cannot be moved. Note that in most cases, when there is a numeric entry beside the widget, you can exceed those ranges if you need by typing in any value manually.
Some filters have additional controls that you work with directly in the View windows. Take the Slice filter for example. Slice extracts slices from the data that lie on a set of parallel planes in oriented in space. You can use textual widgets on the Display Tab to manually specify the exact location and orientation of the slice planes but you often do not need such exact control and it is faster then to orient the slice planes visually. You can do that very easily by clicking on and dragging a 3D Plane widget in the 3D scene.
In the same way that sliders and numeric entry boxes in the Properties tab always stay in synch, the orientation of the drawn plane and the widgets in the Properties tab are always kept in synch too. Again, changes you make with 3D widgets do not take effect until you hit accept and can be undone via the Reset and Undo buttons. For more information about the various widgets, refer to Chapter <????>
Pipeline Basics
Data manipulation in ParaView is fairly unique because of the underlying pipeline architecture that it borrows from VTK. Each filter within the module takes in some data and produces something new from it. Filters do not directly modify the data that is given to them and in order to conserve memory try as much as possible to copy through any data that is unmodified by reference. The fact that input data is not altered means that unlike most visualization packages, you can apply several filtering operations in different combinations to your data during a single ParaView session. You see the result of each filter as it is applied, which helps to guide you data exploration work, and can even display any or all intermediate pipeline outputs simultaneously if you need to.
The Pipeline Browser depicts ParaView's current visualization pipeline and allows you to easily navigate to the various readers, sources, and filters it contains. Connecting an initial data set loaded from a file or created from a ParaView source to a filter creates a two filter long visualization pipeline. The initial data set read in becomes the input to the filter, and if needed the output of that filter can be used as the input to a subsequent filter, etc.
For example, suppose you create a sphere in ParaView by selecting Sphere from the Sources menu. In this example, the sphere is the initial data set. Next create a Shrink filter, available in the Alphabetical submenu of the Filters menu. Because the sphere was the current data set when the shrink filter was applied, it is used as the input to the shrink filter. Use the Properties tab of the Object Inspector set any or all parameters <See Section XXXX below for detail> of the new filter as you see fit and then hit the Apply button. Finally apply an elevation filter to the output of the shrink filter and click Apply again. You have just created a simple, linear pipeline in ParaView. You will see the following in the Pipeline Browser.
Within the Pipeline Browser, to the left of each entry is an eye icon indicating whether that data set is currently visible. If there is no eye icon, it means that the data produced by that filter is not compatible with the currently active View window. Otherwise, a dark eye icon indicates that the data set is visible; and when a data set is viewable but currently invisible, its icon is drawn in light gray. Clicking on the eye icon toggles the visibility of the corresponding data set. In the above example, all three filters are potentially visible, but only the ElevationFilter is actually being displayed. The ElevationFilter is also highlighted in blue, indicating that it is the currently "active" Filter. Since it is the "active" filter, the Object Inspector reflects its content and the next filter created will use it as the input.
Double-clicking the name of one of the filters causes the name to become editable, enabling you to change it to something more meaningful.
Note that you can change parameters after a filter has been applied. Left-clicking the name of one of the filters causes it to become the "active" filter. The Object Inspector's Properties, Display, and Information tabs are always updated to show the current data set. When you make changes in the Properties tab and apply your changes, the filters beyond the current one in the pipeline will be updated to reflect this change.
Right-clicking a data set's name displays a context menu from which you can do several things. For reader modules you can use this to load a new data file. For all modules you can additionally save it as a Custom Filter (see the last section of this chapter), or delete it (if it is at the end of the visualization pipeline). For filter modules you can also use this menu to change the input to the filter, and thus rearrange the visualization pipeline.
To rearrange the pipeline, right-clicking the filter's name in the Pipeline Browser, and y select Change Input from the context menu that appears. Only data sets that meet the qualifications for the input of this filter will be selectable in the dialog for changing inputs.
Note the input editor does not allow the creation of loops in the visualization pipeline, so in the diagram above Clip1 cannot be the input to itself. Left-clicking on one of the possible inputs in the Select Source window causes the Pipeline Preview window to show what the contents of the pipeline browser would be if the input was changed in this way. Clicking OK causes the input to change.
You can not create loops in the pipeline, but you can create branches. Select ShrinkFilter1 in the Pipeline Browser; then apply Extract Edges from the Alphabetical submenu of the Filters menu. Now the output of the shrink filter is being used as the input to both the elevation and extract edges filters. You will see the following in the Pipeline Browser.
Another way to introduce a branch into the Pipeline is to open a reader or filter that produces multiple distinct data sets. An example of this is the SLAC reader that produces both a polygonal output and a structured data field output. With either type of branch you can select one output or the other to make it active and this extend the pipeline from it alone.
Some filters that need to produce multiple data sets do so in a different way. Instead of producing several fundamentally distinct data sets, it is often more convenient to produce a single composite data set which contains some number of sub data sets. (See Chapter ?for a fuller explanation). In this case it is usually more convenient to treat the entire composite data set as one entity and you do not need to do anything in particular to do so. Sometimes though, you want to operate on a particular sub data sets as you can for a multi-output filter. Do so by first apply the Extract Datasets filter to your multi-group data set to extract the desired part(s), and then apply the filter only to the extracted part(s).
{kind=link}
Pipelines are also allowed to contain filters that merge the pipeline, taking in more than one data set to produce their own output (or outputs). There are in fact two different varieties of merging filters. The Append Filter and Group Data Sets filter s are examples of the first kind. These filters take in any number of fundamentally similar data sets. An append filter for example takes in one or more polygonal datasets and combines them into a single large polygonal data set. To use this type of merge filter, select more than one filter within the Pipeline browser by pressing the <SHIFT?> key while you left click. Then instantiate the merging filter from the Filters menu as before. The pipeline in this case will look like the one in the following figure.
{kind=link}
Other filters take in more than one, fundamentally different data sets. An example is the <?Probe With Arbitrary Data?> filter which takes in one data set the represents a field in space to sample values from and another data set which that to find the locations in space to sample the values onto. Begin this type of merge by simply choosing the filter from the Filters menu. When you do, ParaView creates a dialog that you use to identify which of the modules form the Pipeline to use for each input. The dialog is shown below:
{kind=link}
{kind=link}
Available Filters
There are a great many filters available in ParaView, and because ParaView has a modular architecture, it is routine for people to add new filters of their own design. <REFERENCE WIKI PAGE ON PLUGINS/PROGRAMMABLE FILTER>.
The most common filters are all available by clicking on the respective icon in the filters toolbar.
- Calculator - Evaluates a user-defined expression on a per-point or per-cell basis.
- Contour - Extracts the points, curves, or surfaces where a scalar field is equal to a user-defined value. This surface is often also called an isosurface.
- Clip - Intersects the geometry with a half space. The effect is to remove all the geometry on one side of a user-defined plane.
- Slice - Intersects the geometry with a plane. The effect is similar to clipping except that all that remains is the geometry where the plane is located.
- Threshold - Extracts cells that lie within a specified range of a scalar field.
- Extract Subset - Extracts a subset of a grid by defining either a volume of interest or a sampling rate.
- Glyph - Places a glyph, a simple shape, on each point in a mesh. The glyphs may be oriented by a vector and scaled by a vector or scalar.
- Stream Tracer - Seeds a vector field with points and then traces those seed points through the (steady state) vector field.
- Warp - Displaces each point in a mesh by a given vector field.
- Group Datasets - Combines the output of several pipeline objects into a single multi block data set.
- Group Extract Level - Extract one or more items from a multi block data set.
These eleven filters are a small sampling of what is available in ParaView.
In Alphabetical submenu of the Filters menu you will find the entire set of filters that are available in your copy of ParaView. ParaView currently exposes more than one hundred filters, so to make them easier to find the Filters menu is organized into submenus. These submenus are organized as follows.
- Recent - The list of most recently used filters sorted with the most recently used filters on top.
- Common - The most common filters. This is the same list of filters available in the filters toolbar and listed previously.
- Cosmology - This contains filters developed at LANL for cosmology research.
- Data Analysis - The filters designed to retrieve quantitative values from the data. These filters compute data on the mesh, extract elements from the mesh, or plot data.
- Statistics - This contains filters that provide descriptive statistics of data, primarily in tabular form.
- Temporal - Filters that analyze or modify data that changes over time.
All filters can work on data that changes over time because they are executed on each time snapshot. However, filters in this category will introspect the available time extents and examine how data changes over time.
- Alphabetical - An alphabetical listing of all the filters available. If you are not sure where to find a particular filter, this list is guaranteed to have it. There are also many filters that are not listed anywhere but in this list.
Why can't I apply the filter I want?
Note that many of the filters in the menu will be grayed out and not selectable at any given time. That is because any given filter may only operate on particular types of data. For example the <FILTER NAME> will only operate on <DATA TYPE> data so it is only enabled when the module you are building on top of produces <DATA TYPE> data. In this situation you can often find a similar filter that does accept your data, or apply a filter that transforms you data into the required format.
Searching through these lists of filters, particularly the full alphabetical list, can be cumbersome. To speed up the selection of filters, you should use the quick launch dialog. When the ctrl and space keys together on Windows or Linux or the alt and space keys together on Macintosh, ParaView brings up a small, lightweight dialog box like the one shown here. Type in words or word fragments that are contained in the filter name, and the box will list only those sources and filters that match the terms. Hit enter to add the object to the pipeline browser.
What does that filter do?
A description of what each filter does, what input data types it accepts and what output data types it produces can be found in Chapter <REFERENCE FILTER> and within ParaView's help system < LINK TO LOCATION IN REVISED HELP>. For a more complete understanding, remember that most ParaView filters are simply VTK algorithms, each of which is documented online in the VTK Doxygen wiki pages < LINK TO VTK/PV DOXYGEN>.
When one is exploring a given data set, one does not want to have to hunt through the detailed descriptions of all of the filters in order to find the one filter that they need at any given moment. It is useful then to be aware of the general high-level taxonomy of the different operations that the filters are grouped into.
These are:
- Attribute Extraction
- Topological operations
- Data Type Conversion
- White Box Filters
1.4.1 Avoiding Data Explosion
The pipeline model that ParaView presents is very convenient for exploratory visualization. The loose coupling between components provides a very flexible framework for building unique visualizations, and the pipeline structure allows you to tweak parameters quickly and easily.
The downside of this coupling is that it can have a larger memory footprint. Each stage of this pipeline maintains its own copy of the data. Whenever possible, ParaView performs shallow copies of the data so that different stages of the pipeline point to the same block of data in memory. However, any filter that creates new data or changes the values or topology of the data must allocate new memory for the result. If ParaView is filtering a very large mesh, inappropriate use of filters can quickly deplete all available memory. Therefore, when visualizing large data sets, it is important to understand the memory requirements of filters.
Please keep in mind that the following advice is intended only for when dealing with very large amounts of data and the remaining available memory is low. When you are not in danger of running out of memory, ignore all of the following advice.
When dealing with structured data, it is absolutely important to know what filters will change the data to unstructured. Unstructured data has a much higher memory footprint, per cell, than structured data because the topology must be explicitly written out. There are many filters in ParaView that will change the topology in some way, and these filters will write out the data as an unstructured grid, because that is the only data set that will handle any type of topology that is generated. The following list of filters will write out a new unstructured topology in its output that is roughly equivalent to the input. These filters should never be used with structured data and should be used with caution on unstructured data.
- Append Datasets
- Append Geometry
- Clean
- Clean to Grid
- Connectivity
- D3
- Delaunay 2D/3D
- Extract Edges
- Linear Extrusion
- Loop Subdivision
- Reflect
- Rotational Extrusion
- Shrink
- Smooth
- Subdivide
- Tessellate
- Tetrahedralize
- Triangle Strips
- Triangulate
Technically, the Ribbon and Tube filters should fall into this list. However, as they only work on 1D cells in poly data, the input data is usually small and of little concern.
This similar set of filters also output unstructured grids, but they also tend to reduce some of this data. Be aware though that this data reduction is often smaller than the overhead of converting to unstructured data. Also note that the reduction is often not well balanced. It is possible (often likely) that a single process may not lose any cells. Thus, these filters should be used with caution on unstructured data and extreme caution on structured data.
- Clip
- Decimate
- Extract Cells by Region
- Extract Selection
- Quadric Clustering
- Threshold
Similar to the items in the preceding list, Extract Subset performs data reduction on a structured data set, but also outputs a structured data set. So the warning about creating new data still applies, but you do not have to worry about converting to an unstructured grid.
This next set of filters also outputs unstructured data, but it also performs a reduction on the dimension of the data (for example 3D to 2D), which results in a much smaller output. Thus, these filters are usually safe to use with unstructured data and require only mild caution with structured data.
- Cell Centers
- Contour
- Extract CTH Fragments
- Extract CTH Parts
- Extract Surface
- Feature Edges
- Mask Points
- Outline (curvilinear)
- Slice
- Stream Tracer
These filters do not change the connectivity of the data at all. Instead, they only add field arrays to the data. All the existing data is shallow copied. These filters are usually safe to use on all data.
- Block Scalars
- Calculator
- Cell Data to Point Data
- Curvature
- Elevation
- Generate Surface Normals
- Gradient
- Level Scalars
- Median
- Mesh Quality
- Octree Depth Limit
- Octree Depth Scalars
- Point Data to Cell Data
- Process Id Scalars
- Random Vectors
- Resample with dataset
- Surface Flow
- Surface Vectors
- Texture Map to...
- Transform
- Warp (scalar)
- Warp (vector)
This final set of filters are those that either add no data to the output (all data of consequence is shallow copied) or the data they add is generally independent of the size of the input. These are almost always safe to add under any circumstances (although they may take a lot of time).
- Annotate Time
- Append Attributes
- Extract Block
- Extract Datasets
- Extract Level
- Glyph
- Group Datasets
- Histogram
- Integrate Variables
- Normal Glyphs
- Outline
- Outline Corners
- Plot Global Variables Over Time
- Plot Over Line
- Plot Selection Over Time
- Probe Location
- Temporal Shift Scale
- Temporal Snap-to-Time-Steps
- Temporal Statistics
There are a few special case filters that do not fit well into any of the previous classes. Some of the filters, currently Temporal Interpolator and Particle Tracer, perform calculations based on how data changes over time. Thus, these filters may need to load data for two or more instances of time, which can double or more the amount of data needed in memory. The Temporal Cache filter will also hold data for multiple instances of time. Also keep in mind that some of the temporal filters such as the temporal statistics and the filters that plot over time may need to iteratively load all data from disk. Thus, it may take an impractically long amount of time even if does not require any extra memory.
The Programmable Filter is also a special case that is impossible to classify. Since this filter does whatever it is programmed to do, it can fall into any one of these categories.
1.4.2 Culling Data
When dealing with large data, it is clearly best to cull out data whenever possible, and the earlier the better. Most large data starts as 3D geometry and the desired geometry is often a surface. As surfaces usually have a much smaller memory footprint than the volumes that they are derived from, it is best to convert to a surface soon. Once you do that, you can apply other filters in relative safety.
A very common visualization operation is to extract isosurfaces from a volume using the contour filter. The Contour filter usually outputs geometry much smaller than its input. Thus, the Contour filter should be applied early if it is to be used at all. Be careful when setting up the parameters to the Contour filter because it still is possible for it to generate a lot of data. This obviously can happen if you specify many isosurface values. High frequencies such as noise around an isosurface value can also cause a large, irregular surface to form.
Another way to peer inside of a volume is to perform a Slice on it. The Slice filter will intersect a volume with a plane and allow you to see the data in the volume where the plane intersects. If you know the relative location of an interesting feature in your large data set, slicing is a good way to view it.
If you have little a-priori knowledge of your data and would like to explore the data without paying the memory and processing time for the full data set, you can use the Extract Subset filter to subsample the data. The subsampled data can be dramatically smaller than the original data and should still be well load balanced. Of course, be aware that you may miss small features if the subsampling steps over them and that once you find a feature you should go back and visualize it with the full data set.
There are also several features that can pull out a subset of a volume: Clip, Threshold, Extract Selection, and Extract Subset can all extract cells based on some criterion. Be aware, however, that the extracted cells are almost never well balanced; expect some processes to have no cells removed. Also, all of these filters with the exception of Extract Subset will convert structured data types to unstructured grids. Therefore, they should not be used unless the extracted cells are of at least an order of magnitude less than the source data.
When possible, replace the use of a filter that extracts 3D data with one that will extract 2D surfaces. For example, if you are interested in a plane through the data, use the Slice filter rather than the Clip filter. If you are interested in knowing the location of a region of cells containing a particular range of values, consider using the Contour filter to generate surfaces at the ends of the range rather than extract all of the cells with the Threshold filter. Be aware that substituting filters can have an effect on downstream filters. For example, running the Histogram filter after Threshold will have an entirely different effect then running it after the roughly equivalent Contour filter.
Macros (aka Custom Filters)
It often happens that once you figure out how to do some specific data processing task, you will want to repeat that task often. It is very useful to be able to reuse particular filters with exact filter settings (for example complicated calculator or programmable filter expressions) or even entire pipeline sections consisting of a number of filters on different datasets.
You can use of course edit and use state files <REFERENCE BATCH MODE CHAPTER?> to recreate entire ParaView sessions but this does not give you fine enough control for small, highly reusable tasks. Another alternative is to use Python Tracing <REFERENCE PYTHON TRACING>, which does give you fine grained control, but assumes that your have python enabled in your copy of ParaView (which is usually but not always the case) and that you remembered to turn on Trace recording before you did whatever it was that you wanted to be able to play back. ParaView’s Custom Filters suffer from neither of these problems.
A Custom Filter is a black box filter that encapsulates one or more filters in a sub-pipeline and exposes only those parameters from that sub-pipeline that the Custom Filter creator chose to make available. For example, if you have a ten element pipeline in your Custom Filter and each filter in the pipeline has eight controls, you can choose to expose anywhere from zero to eighty controls in your Custom Filter's Properties tab.
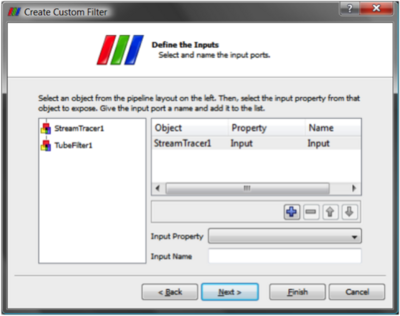
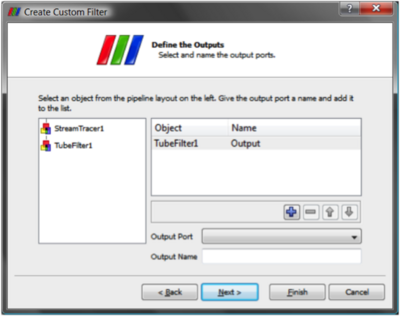
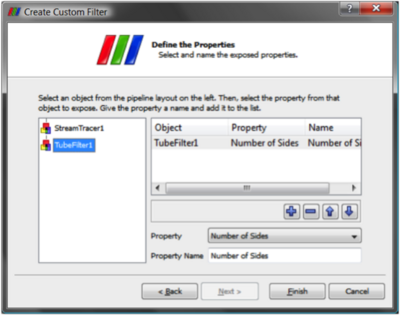
Once you have set up some pipeline that performs the data processing that you want to reuse, the process of creating a Custom Filter consists of three steps. First select one or more filters from the Pipeline Browser using the mouse. Next from the Tools menu select Create Custom Filter. From that dialog choose the module who's input is representative of where you want data to enter into your Custom Filter. This is usually the topmost filter. If you are creating a multi-input filter, use the + button to add more and configure it as well. Clicking Next brings you to a similar dialog that you use similarly to configure one or more outputs of your Custom Filter. Click Next again to get to the last dialog. This dialog is where you specify the parameters of the internal filters that you want to expose to the eventual user of your custom filter. You also are able here to give each parameter a label if you like. The three dialogs are shown below.
 | |
 | |
 |
Once you create a Custom Filter it is added to the Alphabetical sub menu of the Filters menu. It is saved in ParaView's settings, so the next time you start ParaView on the same machine you will have access to your new filter. Custom Filters are treated no differently than other filters in ParaView and are saveable and restorable in state files and python scripts. If you find that you no longer need some Custom Filter, you can use the Tools->Manage Custom Filters dialog box to remove it from your Filters menu.
If on the other hand you find that a Custom Filter is very useful, you may instead want to give it to a colleague. On that same dialog are controls for exporting and importing Custom Filters. When you save a Custom Filter you are prompted for a location and filename to save the filter in, and the filter will be written to that file in an XML text file that you can simply email to share.